[BigData] Naver News Analysis

R을 사용하여서 네이버 뉴스를 분석, 그리고 뉴스 분야를 예측해 보겠습니다. 그러기에 필요한 문제를 파악하고 분석방법 및 예측 모델을 기획한 다음 분석을 시작하겠습니다. 마지막으로, 도출해낸 결과를 시각화함과 동시에 광고 효율을 올리는 것에 대한 제안을 하겠습니다.
Table of Contents
- Table of Contents
- Analysis
- Data Requirement
- Development
- Final Conclusion
- Sources
- Collaborator
Analysis
문제 파악 및 기획 방향 분석
네이버 뉴스를 크롤링하기 전에 웹사이트를 분석하였습니다.
Data Requirement
Data source : https://news.naver.com
| Column | Data Type | Description | Variable Name |
|---|---|---|---|
| Rank | Integer | 뉴스 랭킹 순위 | rank |
| Title | String | 뉴스 제목 | title |
| Subtitle | String | 뉴스 부제목 | subti |
| Source | String | 뉴스를 적은 회사 | source |
| View | Integer | 뉴스 조회 수 | view |
| Comment | Integer | 뉴스 총 댓글 수 | cmt |
| Date | Integer | 뉴스 날짜 | date |
| Current Comment | Integer | 현재 댓글 수 | currCmt |
| Deleted Comment | Integer | 삭제된 댓글 수 | deleted |
| Broken Policy | Integer | 규정 미준수 댓글 수 | brokenPolicy |
| Male Ratio | Integer | 남자 댓글 수 비율 | maleRatio |
| Female Ratio | Integer | 여자 댓글 수 비율 | femaleRatio |
| 10s Ratio | Integer | 10대 댓글 수 비율 | X10 |
| 20s Ratio | Integer | 20대 댓글 수 비율 | X20 |
| 30s Ratio | Integer | 30대 댓글 수 비율 | X30 |
| 40s Ratio | Integer | 40대 댓글 수 비율 | X40 |
| 50s Ratio | Integer | 50대 댓글 수 비율 | X50 |
| 60s Ratio | Integer | 60대 댓글 수 비율 | X60 |
2018년 11월 ~ 2019년 10월은 예측 모델을 위한 training 데이터로 사용할 것이고,
2019년 11월은 예측 모델을 위한 testing 데이터로 사용할 것이다.
Development
0 Crawling
0.1 Initialisation
Data Requirement에 있는 데이터 웹크롤링하기
우선 크롤링을 하기 위해 rvest 와 RSelenium 패키지를 사용했습니다. Selenium을 사용함으로써 rvest로 GET 하거나 POST 하여 가져올 수 없는 웹페이지를 크롤링할 떄 편리합니다. 예를 들어 클릭해서 로그인 후 내용을 크롤링 한다든지, 검색어를 입력해서 크롤링 하는 경우, 웹표준을 지키지 않아서 크롤링이 어려운 경우 등에 사용하면 편리합니다.
RSelenium 을 사용하기 위해서 3개의 드라이버를 다운 받았습니다:
자바 jar 파일입니다. Selenium 서버를 실행하기 위한 툴입니다.
W3C WebDriver 프로토콜을 사용하여 Selenium 과 통신합니다. W3C 는 보편적으로 정의된 표준입니다. 즉, Selenium 개발자들이 각 브라우저 버전별로 Selenium 버전을 계속 개발하지 않아도 된다는 뜻입니다.
이 또한 W3C WebDriver standard를 시행한 독립 서버입니다.
RStudio 에서 gecko driver 를 사용하려면 먼저 관리자 권한으로 CMD를 실행시켜 위파일이 설취된 폴더에 접근하였습니다. 그리고, 다음 명령어를 입력하여 Gecko WebDriver 를 이용해 Selenium 서버를 4445 포트에 실행하였습니다.
java -Dwebdriver.gecko.driver="geckodriver.exe" -jar selenium-server-standalone-3.9.1.jar -port 4445
서버가 성공적으로 실행되면 다음과 같은 출력을 확인할 수 있습니다.
INFO - Selenium Server is up and running on port 4445
다음으로, RStudio에서 원격 드라이버를 실행시키는 코드를 작성하였습니다.
library(RSelenium)
remDr <- remoteDriver(remoteServerAdd='localhost', port=4445L, browserName='chrome')
remDr$open()
저는 ‘Chrome’ 브라우저를 사용하여 로컬 호스트 서버에서 미리 명시한 4445번 포트로 remoteDriver 를 실행시켰습니다.
성곡적으로 실행시킨 경우, 새로운 Chrome 창이 떴습니다.
0.2 URL analysis
크롤링할 사이트 url 을 분석 후 baseurl 을 url 변수에 저장하였습니다.
url <- 'https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day§ionId=100&date='
- sectionId 는 뉴스 분야를 나타내는 고유값이다. 100부터 105까지 총 6개의 section(정치, 경제, 사회, 생활/문화, 세계, IT/과학) 입니다.
- date 는 날짜를 나타내므로, 형식은 20181101 처럼 8자리 숫자를 입력합니다.
0.3 Exceptions
‘Data Requirement’ 에서 말했듯이 Training 데이터는 1년치 데이터이고, Testing 데이터는 1개월 데이터입니다. 먼저 for 문을 돌리기 위한 변수들을 만들었습니다.
더 나아가, 크롤링 시작하는 날짜와 끝나는 날짜도 변수에 하고 크롤링 시작 및 탈출을 하기 위한 flag 논리 변수도 생성하였습니다.
이제 for 문 속 예외 처리를 확인해 보겠습니다.
for(y in year) {
if(finFlag == T) { break }
if(as.integer(y) < as.integer(str_sub(startDate, 1, 4)) & isFALSE(startFlag)) { next }
mcnt <- 0 # Index to iterate month_eng vector
for(m in month) {
mcnt <- mcnt + 1 # Incrementing index
if(finFlag == T) { break }
if(as.integer(m) < as.integer(str_sub(startDate, 5, 6)) & isFALSE(startFlag)) { next }
for(d in day) {
if(finFlag == T) { break }
if(as.integer(d) < as.integer(str_sub(startDate, 7, 8)) & isFALSE(startFlag)) { next }
# Discard months with no 31st (except February)
if(m %in% c('04','06','09','11') & d == 31) { next }
# Discard February (special cases)
if(m %in% c('02') & d >= 30) { next }
if(isFALSE(startFlag)) { startFlag = T }
dat <- paste(y, m, d, sep='')
if(dat == stopDate) { finFlag = T }
...
}
}
}
먼저 for 문을 도는 변수가 크롤링 시작날짜 startDate 변수와 일치할 때까지 다음 반복문으로 넘어가고, 크롤링 마치는날짜 stopDate 변수와 일치할 경우 그 반복문을 마지막으로 실행하고 반복문을 탈출 할 수 있게 설계하였습니다.
day 변수를 반복처리 하면서 이런경우 다음 반복문으로 넘어가도록 설계했습니다 :
- 31일이 없는 월일 경우 (4월, 6월, 9월, 11월)
- 2월 30일 또는 31일인 경우
이 모든 예외처릴 거치고도 day 변수 반복문에 있다는 것은 3개의 반복문이 startDate 와 일치하다는 뜻으로 크롤링이 시작할 준비가 되었다는 뜻입니다. 그러므로 이때 startFlag 변수를 True 으로 바꾸어 줍니다. 그리고, dat 변수에 url 변수 속 date를 지정할 때 넣을 값 (8자리 숫자배열) 을 저장합니다.
마지막으로, dat 변수가 stopDate 와 일치할 경우 finFlag 를 True 값으로 바꾸어줍니다.
mcnt 변수는 마지막에 모은 크롤링 데이터를 가지고 엑셀 파일에 저장할 때 필요한 index 변수입니다. 이는 나중에 데이터 저장을 다루는 챕터에서 다루겠습니다.
0.4 rvest Crawling
특별한 반응이 필요없는 일반적인 크롤링은 rvest 패키지 함수를 사용했다. 일반적인 파싱으로 기사의 제목, 부제, 언론사, 그리고 조회 수 및 댓글 수를 크롤링하였습니다.
기사 댓글에 대한 세부적인 정보들은 rvest 패키지로 접근이 불가능하여 이런 상황을 위해 만들어진 RSelenium 패키지를 사용하였습니다. RSelenium 을 사용한 크롤링은 다음에 설명 하겠습니다.
먼저 rvest 패키지를 활용한 크롤링입니다. 접근하고 싶은 URL 을 가지고 read_html() 함수를 사용하였습니다.
html <- chkURL(url)
# Checks URL
while(is.list(html) == F) {
html <- chkURL(url)
}
list <- html %>% html_nodes('.ranking_list') %>% html_nodes('.ranking_text')
title <- list %>% html_nodes('.ranking_headline') %>% html_nodes('a') %>% html_text()
subti <- list %>% html_nodes('.ranking_lede') %>% html_text()
source <- list %>% html_nodes('.ranking_office') %>% html_text()
view <- list %>% html_nodes('.ranking_view') %>% html_text()
len <- length(title) # number of articles in this page
if(len == 0) { next } # If nothing is crawled, skip
if(length(view) == 0) { view <- rep(NA, len) }
처음으로 url 변수를 chkURL() 함수의 매개변수로 사용하여 html 변수에 넣습니다. chkURL() 함수는 커스텀 함수이며, tryCatch() 함수를 사용합니다. 이 함수는 read_html() 를 시도하는 중 error 나 warning 이 뜨면 False 값을 리턴하는 함수입니다. 만약에 성공적이었으면 그대로 파싱한 웹사이트를 리스트 데이터 타입으로 리턴합니다.
그 이후에 만약에 html 변수가 리스트 타입이 아니라면 파싱이 잘못된 것이므로 리스트 타입일 때까지 while 문을 돌려서 파싱을 시도합니다.
찾고싶어하는 정보들이 모두 ol 태그내에 있는 div 태그내에 있어서 list 변수에 ranking_text 클래스를 가지고 있는 태그들을 모두 불러 저장하였습니다.
이 때, html_nodes() 함수를 사용하여 접근하고 싶은 class 는 . 을, id 는 # 을 사용하면 그 이름의 class 또는 id 를 가지고 있는 요소에 모두 접근이 가능합니다.
그리고 필요한 데이터들을 다음과 같이 태그를 따라가서 각각의 변수에 저장하였습니다 :
- 기사 제목 : ranking_text > ranking_headline > a 태그. 텍스트를 불러와 title 에 저장
- 기사 부제 : ranking_text > ranking_lede. 텍스트를 불러와 subti 에 저장
- 언론사 : ranking_text > ranking_office. 텍스트를 불러와 source 에 저장
- 조회 수 : ranking_text > ranking_view. 숫자를 불러와 view 에 저장
- 댓글 수 : ranking_text > count_cmt. 숫자를 불러와 *cmt 에 저장
title 변수의 길이를 len 변수에 저장하는 이유는 2018년도 중 아주 가끔 이상치로 인해 아무것도 파싱 되지 않는 경우를 대비하여 다음 반복문으로 건너뛰었습니다.
또한, view 변수에 아무것도 파싱 되지 않는 경우에 NA 값을 len 변수의 숫자만큼 넣었습니다. 댓글 수 관련 크롤링때 같은 일이 일어난다면 cmt 변수에 NA 값을 len 변수의 숫자만큼 넣었습니다.
0.5 RSelenium Crawling
RSelenium 을 사용하여 크롤링을 할 때 ‘많이 본 뉴스’ 페이지와 ‘댓글 많은’ 패이지를 따로 크롤링하였습니다.
0.5.1 Most Viewed Page
크롤링을 시작하기 전의 변수 초기화 작업을 했습니다.
urls <- list %>% html_nodes('.ranking_headline') %>% html_nodes('a') %>% html_attr('href')
iter <- c(1:length(title))
먼저 기사들의 URL 주소들을 벡터 타입의 urls 변수에 저장하였습니다. 요소 접근 방법은 rvest 패키지을 사용해 위와 동일합니다.
반복문에 사용될 뉴스들의 랭킹 숫자들을 iter 변수에 저장했습니다. 이 때, 그냥 1부터 30까지 하지 않은 이유는 뉴스 기사가 각 분야마다 하루에 꼭 30개가 있다는 보장이 없기 때문입니다. 따라서, 30개 미만일 때를 대비하는 설계였습니다.
RSelenium 패키지를 사용해 파싱할 데이터들은 ‘현재 댓글 수’, ‘삭제된 댓글 수’, 등 각 기사마다 총 11개의 데이터입니다.
기사의 댓글 정보를 가지고 있는 URL 주소로 찾아가기 위해서는 기사의 ‘oid’, ‘aid’, 날짜, 그리고 뉴스의 랭킹이 필요했습니다.
for(i in iter) {
url <- 'https://news.naver.com/main/ranking/read.nhn?'
u <- urls[i]
oid <- u %>% str_extract('oid=[0-9]+') %>% str_sub(5)
aid <- u %>% str_extract('aid=[0-9]+') %>% str_sub(5)
url <- paste(url, 'm_view=1&rankingType=popular_day&oid=', oid,'&aid=', aid, '&date=', dat, '&type=1&rankingSectionId=100&rankingSeq=', i, sep='')
remDr$navigate(url)
...
}
위 코드는 iter 변수를 반복하는 for 문 내의 코드입니다. 먼저 baseURL 을 url 변수에 저장했습니다.
그 다음 urls 에 저장되어있는 기사 URL 에서 oid 와 aid 를 추출하였습니다. 이 때, stringr 패키지의 str_extract() 와 str_sub() 함수를 사용했습니다. str_extract() 함수를 사용하면 ‘oid=123456’ 와 같이 데이터가 추출이 됩니다. 이 때, 숫자만 필요하기 떄문에 str_sub() 함수를 사용하여 추출된 문자열 데이터에서 5번째 자리부터 끝까지 즉, 숫자만 추출하였습니다.
url 변수에 최종 URL 을 저장한 다음 remoteDriver 의 navigate() 함수의 매개변수로 삽입하면 chrome 창이 그 주소로 이동합니다.
마지막으로 그 주소에서 필요한 데이터를 추출합니다.
sleepT <- 1/4
...
Sys.sleep(sleepT)
elm <- remDr$findElements('class','u_cbox_info_txt')
cnt <- 1
while(length(elm) == 0) { # If nothing is crawled, then refresh the page and wait longer
remDr$navigate(url)
Sys.sleep(sleepT * 2^cnt)
elm <- remDr$findElements('class','u_cbox_info_txt')
cat(sleepT * 2^cnt, '\n')
cnt <- cnt + 1
}
chrome 에서 페이지가 모두 로드되지 않은 상태에서 파싱하여 에러 뜨는 것을 방지하기 위해 Sys.sleep() 함수를 사용해 작업을 일정 시간 동안 멈추었습니다. 이 때 사용한 sleepT 변수는 코딩 초기화 하는 부분에서 0.25 라는 값으로 세팅 해 놓았습니다.
HTML 요소를 찾을 떄 remoteDriver 의 findElements() 함수를 사용합니다. 매개변수에는 무엇으로 찾고자 하는지, 무엇을 찾고 있는지를 지정합니다. 저는 ‘u_cbox_info_txt’ 를 class 로 가지고 있는 요소들을 찾고 싶어 위와 같이 코딩하였습니다. 그리고 파싱된 데이터를 elm 변수에 저장했습니다.
만약에 0.25 초를 기다리고도 로딩이 되지 않은 페이지에서 요소를 접근하려고 할 시에 elm 변수에는 아무것도 파싱되지 않습니다. 따라서, elm 변수는 길이가 0 이 됩니다. 그럴 경우 while 문을 돌려서 sleepT 변수의 값을 기하급수적으로 늘립니다. 그렇게 ‘새로고침’을 한 다음 또 다시 sleepT 의 값 만큼 대기합니다. 이렇게 elm 변수의 길이가 0 이 아닐 떄 까지 ‘새로고침’을 시도합니다.
currCmt <- cleanc(c(currCmt, as.character(elm[[1]]$getElementText())))
if(is.na(as.integer(currCmt[i]))) { # If current comment is not crawled, change to NA
currCmt[i] = NA
deleted <- c(deleted, NA)
brokenPolicy <- c(brokenPolicy, NA)
maleRatio <- c(maleRatio, NA)
femaleRatio <- c(femaleRatio, NA)
X10 <- c(X10, NA)
X20 <- c(X20, NA)
...
next()
}
지금 elm 변수에는 ‘u_cbox_info_txt’ 를 class 로 가지고 있는 요소들이 리스트 타입으로 들어가 있습니다. 그리고 그 첫번째 요소에 현재 댓글 수가 들어가 있습니다. 그리고 그 요소에 있는 숫자를 getElementText() 함수를 이용하여 불러옵니다. 파싱된 데이터를 as.character() 함수로 문자열로 변환했습니다. 그 이후, cleanc() 라는 커스텀 함수를 사용해서 다음과 같이 , 를 없애줍니다.
콤마를 없앨 때는 간단하게 gsub() 라는 함수를 사용했습니다. 그렇게 데이터 전처리가 끝난뒤에 currCmt 변수에 저장했습니다.
만약에 아무것도 파싱되지 않은 경우, 데이터가 없다는 뜻으로 이후에 크롤링 할 데이터를 NA 값으로 대치 시켰고 다음 반복문으로 넘어가도록 설계했습니다.
deleted <- c(deleted, as.character(elm[[2]]$getElementText()))
brokenPolicy <- c(brokenPolicy, as.character(elm[[3]]$getElementText()))
if(as.integer(currCmt[i]) < 100) { # If current comment count is less than 100, append NA values to the rest
maleRatio <- c(maleRatio, NA)
femaleRatio <- c(femaleRatio, NA)
X10 <- c(X10, NA)
X20 <- c(X20, NA)
...
next()
}
다음으로 ‘삭제된 댓글 수’ 와 ‘규정 미준수 댓글 수’ 를 elm 변수의 두번째와 세번째 요소들의 값을 다시 getElementText() 함수를 이용하여 불러와 문자열로 변환한 뒤 각각 deleted 와 brokenPolicy 변수에 저장하였습니다.
네이버에서 현재 댓글 수가 100개 미만일 경우 댓글에 관한 데이터를 제공하지 않습니다. 따라서, 남자 댓글 비율, 여자 댓글 비율, 등을 모두 NA 값으로 대치하였습니다. 그리고 다음 반복문으로 넘어가도록 설계했습니다.
elm <- remDr$findElements('class','u_cbox_chart_per')
cnt <- 1
while(length(elm) == 0) { # If nothing is crawled, then refresh the page and wait longer
remDr$navigate(url)
Sys.sleep(sleepT * 2^cnt)
elm <- remDr$findElements('class','u_cbox_chart_per')
cat(sleepT * 2^cnt, '\n')
cnt <- cnt + 1
}
maleRatio <- c(maleRatio, as.character(elm[[1]]$getElementText()))
femaleRatio <- c(femaleRatio, as.character(elm[[2]]$getElementText()))
X10 <- c(X10, as.character(elm[[3]]$getElementText()))
X20 <- c(X20, as.character(elm[[4]]$getElementText()))
...ㄴ
마지막으로 ‘u_cbox_chart_per’ 을 class 로 가진 요소들을 찾아 elm 변수에 저장했습니다. 만약 아무것도 파싱이 되지 않았으면 페이지가 로딩 되기 전에 파싱을 시도 했다는 뜻으로, while 문을 돌리며 페이지를 계속 ‘새로고침’ 하였습니다.
파싱이 끝나면 다시 getElementText() 함수를 사용해 남자 댓글 비율, 여자 댓글 비율, 10대 댓글 비율, 20대 댓글 비율, 등 나머지 데이터를 파싱하여 각각의 벡터 타입 변수에 저장하였습니다.
infoDF <- data.frame(currCmt=currCmt, deleted=deleted, brokenPolicy=brokenPolicy, maleRatio=maleRatio, femaleRatio=femaleRatio, X10=X10, X20=X20, X30=X30, X40=X40, X50=X50, X60=X60)
# pre-processing
subti <- clean(subti) # removes whitespace, \t, \r, \n
view <- cleanc(view); view <- clean(view) # removes commas
tdf <- data.frame(rank=c(1:len), title=title, subti=subti, source=source, view=view, date=rep(dat, len))
tdf <- cbind(tdf, infoDF)
df <- rbind(df, tdf)
댓글에 관한 데이터를 모두 크롤링한 다음 infoDF 데이터프레임에 저장합니다.
부제와 조회 수는 clean() 커스텀 함수를 사용해 엔터, 탭, 등을 없애줍니다. 그리고, 조회 수 벡터 는 다시 한번 cleanc() 함수를 사용해 콤마를 제거해줍니다.
rvest 를 사용해 크롤링한 데이터는 tdf 데이터 프레임에 저장합니다. 그리고 cbind() 함수를 통해 infoDF 와 tdf 데이터 프레임을 합쳐줍니다. 이렇게 tdf 에는 1일 데이터가 저장됩니다.
마지막으로, rbind() 함수를 통해 df 와 tdf 를 연결하였습니다. 이렇게 for 문이 끝나면 한달 데이터가 df 에 저장되어있습니다.
sheName <- paste(month_eng[mcnt], sep='')
file <- paste('D:/GitHub/tjproject/resources/', y, '_view_data_politics.xlsx', sep='')
write.xlsx(df, file, sheetName=sheName, col.names=T, row.names=F, append=T, password=NULL, showNA=T)
최종적으로, 파일에 저장하는 과정입니다. 먼저, 엑셀에 저장할 것이므로 시트이름을 sheName 에 저장합니다. 이 때, index 로 사용되는 mcnt 변수를 사용해서 month_eng 벡터 에서 영어로된 월 이름을 부릅니다. month_eng 는 처음에 초기화 해두었습니다.
파일 이름은 연도, ‘view_data’, 뉴스 분류, 그리고 파일 확장명인 ‘.xlsx’ 을 합쳤습니다.
엑셀 파일로 저장할 때는 xlsx 패키지를 사용했습니다. write.xlsx() 함수를 사용해 다음과 같은 옵션을 주어서 저장했습니다:
- sheetName : 시트 이름을 넣습니다
- col.names : 컬럼이름을 허용할지 안할지 정합니다
- row.names : 행 이름을 허용할지 안할지 정합니다
- append : 같은 파일에 시트를 추가할지 안할지 정합니다
- password : 파일에 비밀번호를 넣습니다
- showNA : NA 값을 보여줄지 안 보여줄지 정합니다
0.5.2 Most Commeneted Page
‘댓글 많은’ 페이지를 크롤링하는 방법은 그 전과 매우 비슷합니다. 하지만, 이번에는 oid 와 aid 를 사용하지 않아도 됩니다. 뉴스 댓글에 관한 정보 페이지로 가는 URL 주소를 바로 불러 올 수 있기 떄문입니다. 이 작업은 rvest 패키지를 사용합니다.
urls <- list %>% html_nodes('.count_cmt') %>% html_attr('href')
urls 변수에 또 다시 URL 주소들을 저장합니다. 하지만, 이번 URL 주소들은 바로 뉴스 댓글 정보 사이트로 이동합니다.
url <- 'https://news.naver.com'
url <- paste(url, urls[i], sep='')
remDr$navigate(url) # navigate to the corresponding news article
또 다시 iter 반복문을 돌면서 위와 같이 더 쉽게 이동합니다. 이 밑으로는 RSelenium 패키지를 사용한 ‘조회 수 많은’ 페이지를 크롤링하는 것과 동일합니다.
sheName <- paste(month_eng[mcnt], sep='')
file <- paste('D:/GitHub/tjproject/resources/', y, '_comment_data_life_cult.xlsx', sep='')
write.xlsx(df, file, sheetName=sheName, col.names=T, row.names=F, append=T, password=NULL, showNA=T)
파일을 저장할 때는 위와 같이 ‘view_data’ 대신 ‘comment_data’ 라고 파일명을 짓습니다.
1 Database - MySQL
엑셀 파일에서 데이터를 불러오는 시간이 생각보다 매우 오려걸려 MySQL 데이터베이스를 사용하여 관리하기로 하였습니다. 이를 위해 MySQL 을 설치 후 R 에서 RMySQL 과 DBI 패키지를 사용해 데이터를 불러왔습니다.
conn <- dbConnect(MySQL(), user="naver", password="Naver1q2w3e4r!", dbname="naverdb",host="localhost")
DBI 패키지의 dbConnect() 함수를 사용해 올바른 매개변수를 넣어 실행시키면 아무 에러 없이 conn 객체가 생성됩니다.
이제 엑세에서 데이터를 불러와서 database 에 집어 넣기만 하면 됩니다.
1.1 Initialisation
db 에 접근하기 앞서, 변수 초기화를 해보겠습니다.
ext <- '.xlsx'
path <- 'resources/'
types <- c('E','I','L','P','S','W')
sections <- c('econ','IT','life_cult','politics','soc','world')
tables <- c('NEWS_ECON', 'NEWS_IT', 'NEWS_LIFE_CULT', 'NEWS_POLITICS', 'NEWS_SOC', 'NEWS_WORLD')
- ext : 파일 불러 올때의 확장명
- path : 엑셀파일이 들어가있는 파일 이름
- types : NEWSID 라는 Primary Key 를 생성할 때 필요한 변수
- sections : 파일 불러 올때 필요한 뉴스 분야 이름을 저장한 변수
- tables : DB 에 저장되어있는 테이블 이름들을 저장한 변수
DB 에 6개의 테이블을 생성하였습니다. 6개의 테이블은 각 뉴스 분류 별로 생성한 것 입니다. 다음은 테이블 생성할 때 사용한 SQL 코드 입니다.
USE naverdb;
CREATE TABLE NEWS_POLITICS(
NEWSID varchar(16) PRIMARY KEY,
NEWSRANK INT,
TITLE varchar(512),
SUBTITLE varchar(512),
SRC varchar(32),
NEWSDATE varchar(16),
NVIEW INT,
NCOMMENT INT,
CURR_CMT INT,
DELETED INT,
BROKEN INT,
MALER INT,
FEMALER INT,
X10 INT,
X20 INT,
X30 INT,
X40 INT,
X50 INT,
X60 INT
);
보시다시피 19개의 컬럼을 사용하였습니다. 각 컬럼은 다음을 나타냅니다 :
- NEWSID : 뉴스 기사 고유 아이디 (이것은 네이버에서 제공된 것이 아닌 저희가 정한 커스텀 아이디입니다)
- NEWSRANK : 뉴스 랭킹
- TITLE : 뉴스 기사 제목
- SUBTITLE : 뉴스 기사 부제
- SRC : 언론사
- NEWSDATE : 작성된 날짜
- NVIEW : 조회 수
- NCOMMENT : 전체 댓글 수
- CURR_CMT : 현재 댓글 수
- DELETED : 삭제된 댓글 수
- BROKEN : 규정 미준수 댓글 수
- MALER : 남자 댓글 수 비율
- FEMALER : 여자 댓글 수 비율
- X10 : 10대 댓글 수 비율
- X20 : 20대 댓글 수 비율
- X30 : 30대 댓글 수 비율
- X40 : 40대 댓글 수 비율
- X50 : 50대 댓글 수 비율
- X60 : 60대 댓글 수 비율
1.2 Functions
DB 에 데이터를 전송하기 위해 3개의 함수를 사용했습니다.
1.2.1 dbsend()
이 함수에는 4개의 매개변수가 들어갑니다.
- df : DB 에 삽입할 데이터가 들어있는 데이터 프레임
- type : 뉴스 기사 분류 코드
- tab : 데이터를 삽입할 DB 속 테이블 이름
NEWSID, NEWSDATE 외의 컬럼은 데이터 가공이 필요하지 않고 데이터프레임에서 바로 테이블로 삽입이 가능함으로 다른 설명이 굳이 필요가 없습니다.
len <- nrow(df)
for(l in c(1:len)) {
DATE <- paste(str_sub(date[l], 1, 4), '/', str_sub(date[l], 5, 6), '/', str_sub(date[l], 7, 8), sep='')
NEWSDATE <- c(NEWSDATE, DATE)
}
NEWSDATE 컬럼 데이터 가공 코드입니다. 연, 월, 일 사이에 ‘/’ 를 넣어주고 NEWSDATE 벡터에 저장합니다.
NEWSID <- c()
if(is.null(NVIEW)) {
NVIEW <- rep(0, len)
for(l in c(1:len)) {
ID <- paste(type, 'C', date[l], NEWSRANK[l], sep='')
NEWSID <- c(NEWSID, ID)
}
}
else {
NCOMMENT <- rep(0, len)
for(l in c(1:len)) {
ID <- paste(type, 'V', date[l], NEWSRANK[l], sep='')
NEWSID <- c(NEWSID, ID)
}
}
저는 DB 에 조회 수 많은 기사 데이터 및 댓글 많은 기사 데이터를 모두 각 기사 분류에 따라 삽입하므로 NVIEW 컬럼과 NCOMMENT 컬럼중 하나는 무조건 NULL 값이 들어갑니다. 따라서, 먼저 NVIEW 가 NULL 인지 확인합니다. 만약에 NULL 이면, 0을 len 변수 값 만큼 넣습니다. 먼약 NCOMMENT 가 NULL 일 경우 반대로 시행합니다.
NEWSID 는 뉴스 분류 코드, ‘V’ 또는 ‘C’, 날짜, 랭킹을 합친 것을 뉴스 아이디로 사용하며 DB 에서의 Primary Key 로 사용하고 있습니다. ‘조회 수 많은’ 페이지의 데이터면 ‘V’를, ‘댓글 많은’ 페이지의 데이터면 ‘C’를 사용합니다.
for(i in c(1:len)) {
if(is.na(X10[i])) {
MALER[i] <- 0
FEMALER[i] <- 0
X10[i] <- 0
X20[i] <- 0
X30[i] <- 0
X40[i] <- 0
X50[i] <- 0
X60[i] <- 0
}
}
또 다른 예외 처리로 ‘10대 댓글 비율’이 NA 값인 경우 비율 데이터에 아무것도 안 들어왔다는 의미로 0으로 대치하여 삽입하였습니다.
for(i in c(1:len)) {
if(is.na(CURR_CMT[i])) {
CURR_CMT[i] <- 0
DELETED[i] <- 0
BROKEN[i] <- 0
}
}
현재 댓글 수가 NA 값인 경우 ‘현재 댓글 수’, ‘삭제된 댓글 수’, ‘규정 미준수 댓글 수’ 모두 아무것도 파싱 되지 않았다는 뜻임으로, 0으로 대치하여 삽입하였습니다.
for(l in c(1:len)) {
query <- paste("INSERT INTO ", tab, " VALUES(\'",
NEWSID[l], '\', ',
NEWSRANK[l], ', \'',
TITLE[l], '\',\'',
SUBTITLE[l], '\',\'',
SRC[l], '\',\'',
NEWSDATE[l], '\', ',
NVIEW[l], ', ',
NCOMMENT[l], ', ',
CURR_CMT[l], ', ',
DELETED[l], ', ',
BROKEN[l], ', ',
MALER[l], ', ',
FEMALER[l], ', ',
X10[l], ', ',
X20[l], ', ',
X30[l], ', ',
X40[l], ', ',
X50[l], ', ',
X60[l], ")",
sep='')
dbSendQuery(conn, query)
}
위는 query 문을 DBI 패키지의 dbSendQuery() 함수를 사용하여 각 행의 데이터를 for 문을 사용해 DB 에 집어넣는 코드입니다.
1.2.2 cleanData()
cleanData() 함수는 뉴스 기사의 제목과 부제에서 ", ,, ', 그리고 tab 을 없애주는 함수입니다.
cleanData <- function(df) {
df$title <- str_replace_all(df$title, '\"', ' ')
df$title <- str_replace_all(df$title, ',', ' ')
df$title <- str_replace_all(df$title, '\'', ' ')
df$title <- str_replace_all(df$title, '\t', '')
...
return(df)
}
stringr 패키지의 str_replace_all() 함수를 사용해 불필요한 문자들을 공백으로 바꾸어서 없애줍니다.
1.2.3 dbDisconnectAll()
현재 conn 객체를 통해 만들어진 DB 와의 연결을 모두 끊어주는 함수입니다.
dbDisconnectAll <- function(){
ile <- length(dbListConnections(MySQL()))
lapply( dbListConnections(MySQL()), function(x) dbDisconnect(x) )
cat(sprintf("%s connection(s) closed.\n", ile))
}
DBI 패키지의 dbListConnections() 함수를 사용합니다. 리턴된 리스트의 요소 갯수를 ile 변수에 저장하고 lapply() 함수를 사용해 리턴된 connection 들에 dbDisconnect() 함수를 사용해 모두 접속을 끊어줍니다.
1.3 Data Insertion
이제 여기까지의 함수들을 가지고 엑셀 파일을 불러와 데이터를 집어 넣어 보도록 하겠습니다.
for(i in c(1:6)) {
type <- types[i]
section <- sections[i]
tab <- tables[i]
fpath <- paste(path, section, '/2018_view_data_', section, ext, sep='')
for(i in c(1:2)) {
df <- read.xlsx(fpath, sheet=i, colNames=T, rowNames=F)
df <- cleanData(df)
dbsend(df, type, section, tab)
cat('-', i, '-\n')
}
...
}
dbDisconnectAll()
뉴스 기사 분류가 6개이기 떄문에 첫 for 문을 6번 돌립니다. 2018년 데이터는 11월, 12월 총 2개월이 있으니까 for 문을 2번씩 돌립니다. 마지막으로 2019년 데이터는 1월부터 10월 까지 총 10개월이 있으니까 for 문을 10번씩 돌립니다.
그리고 마지막으로 dbDisconnectAll() 함수를 사용해 conn 객체들을 모두 닫아줍니다.
1.4 Data Select
DB 에 올라간 데이터를 받아오는 함수를 모아둔 스크립트를 base 파일에 저장해 두었습니다. 데이터를 삽입했을 때와 같이 conn 객체를 다시 생성합니다.
getSectionData <- function(section, type) {
query01 <- paste('select * from news_',section,' where newsid like "%',type,'%"',
'and newsid not like "%1911%"', sep = '')
dfOne <- dbGetQuery(conn, query01)
return(dfOne)
}
위 코드는 getSectionData() 함수입니다. 다음은 매개변수의 설명입니다 :
- section : 원하는 뉴스 기사 분류의 이름을 집어넣습니다
- type : ‘C’ 는 ‘댓글 많은’ 데이터를, ‘V’ 는 ‘조회 수 많은’ 데이터를 불러옵니다
2019년 11월 데이터는 테스트 데이터이므로 NOT LIKE 를 사용해 SELECT 문에서 불러오지 않게 합니다.
2 Chi-Squared Test
네이버 뉴스의 각 분류의 월별 댓글 및 조회 수가 일 년 평균의 댓글 및 조회 수와 차이가 있는지를 검정했다.
2.1 Monthly View Data
귀무 가설 : 각 분류의 조회 수는 일 년 평균의 조회 수와 차이가 없다.
데이터는 각 분류의 월별 view 합계를 사용했으며, 각 행은 1월부터 12월까지 입니다.
2.1.1 Data Pre-processing
먼저 getSectionData() 함수를 사용해서 데이터를 불러옵니다.
sections <- c("econ", "IT", "life_cult", "politics", "soc", "world")
...
type <- 'V'
Edf <- getSectionData(sections[1], type)
Idf <- getSectionData(sections[2], type)
...
데이터 가공을 하기 위해 getMonthlyView() 함수를 만들었습니다.
getMonthlyView <- function(df) {
len <- nrow(df)
x1 <- c()
x2 <- c()
...
# get NView(7th col)
for(l in c(1:len)) {
month <- df[l,6] %>% str_sub(6, 7)
if(month == "01") { x1 <- c(x1, df[l,7]) }
if(month == "02") { x2 <- c(x2, df[l,7]) }
...
}
x1 <- sum(as.numeric(x1))
x2 <- sum(as.numeric(x2))
...
mViewTotal <- c(x1, x2, x3, x4, x5, x6, x7, x8, x9, x10, x11, x12)
return(mViewTotal)
}
그리고 리턴된 값들을 각 변수에 저장합니다.
EmViewTotal <- getMonthlyView(Edf)
ImViewTotal <- getMonthlyView(Idf)
...
그리고 6개의 벡터를 데이터프레임으로 모와줍니다.
ViewTotaldf <- data.frame(
Economy=EmViewTotal,
IT=ImViewTotal,
Life_Cult=LmViewTotal,
Politics=PmViewTotal,
Society=SmViewTotal,
World=WmViewTotal
)
ViewTotaldf$Month <- c("Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec")
그렇게 되면 아래와 같은 데이터프레임이 완성됩니다.
| Month | Economy | IT | Life_Cult | Politics | Society | World |
|---|---|---|---|---|---|---|
| Jan | 100360767 | 24318368 | 66185551 | 94377073 | 224854699 | 56742533 |
| Feb | 82605339 | 26571839 | 60148342 | 81224742 | 195040992 | 52918607 |
| Mar | 92725836 | 22961125 | 81840238 | 102367831 | 274495875 | 69620547 |
| Apr | 64376011 | 26225649 | 29612244 | 90189555 | 171676720 | 45618439 |
| May | 58151423 | 17556183 | 30631936 | 79373214 | 143327966 | 49052918 |
| Jun | 47012168 | 15552585 | 36170789 | 69076368 | 148542046 | 54264870 |
| Jul | 74764867 | 20546391 | 47437879 | 80397013 | 155554583 | 66601541 |
| Aug | 81484980 | 31272142 | 64107155 | 99438941 | 149975828 | 86008202 |
| Sep | 59604523 | 28324852 | 58441438 | 113892992 | 152266161 | 63514743 |
| Oct | 56800322 | 27399146 | 53852995 | 90718911 | 163767600 | 67452310 |
| Nov | 184035809 | 36879388 | 80367084 | 178246245 | 383292716 | 66053212 |
| Dec | 106837908 | 26320105 | 88204415 | 45959082 | 242464417 | 74342050 |
2.1.2 Visualisation
시각화를 위해 reshape2 패키지의 melt() 함수를 사용합니다.
ViewPlotData1 <- melt(ViewTotaldf, id.vars="Month")
하지만, 이대로 그래프를 그리게 되면 x 축의 레이블이 저희가 원하는 순서대로 나오지 않게 됩니다. 그래서 Month 컬럼을 factor 로 바꿔서 저희가 원하는 순서로 정해줍니다.
xorder <- c("Nov","Dec","Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct")
ViewPlotData1$Month <- factor(ViewPlotData1$Month, levels=xorder, labels=xorder)
이렇게 한 결과, 아래와 같은 그래프를 뽑을 수 있었습니다.
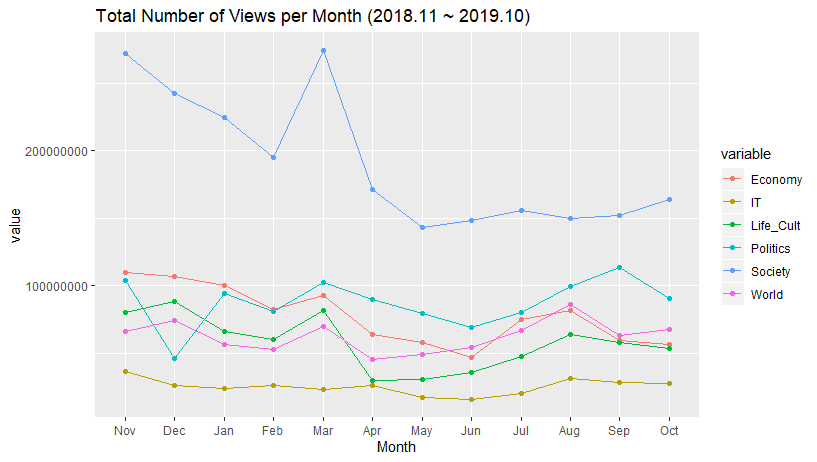
options("scipen" = 100)
ViewPlot1 <- ggplot(ViewPlotData1, aes(Month, value, col=variable)) +
geom_point() +
geom_line(aes(color=variable, group=variable)) +
labs(title="Total Number of Views per Month (2018.11 ~ 2019.10)")
ViewPlot1
위 그래프를 보면 일 년간의 조회 수의 추이를 볼 수 있습니다.
- IT 를 제외하면 대체로 변동폭이 큰것으로 보입니다
- 사회 기사 조회 수가 일년동안 1위를 차지하고 있습니다
- 반면, IT 기사는 조회 수가 꼴지를 기록하고 있으며, 사람들의 관심이 가장 낮은 것으로 보입니다
2.1.3 Test
그래프로 확인 할 수 있는 부분을 카이 제곱 분석을 통해 확인해 보겠습니다. 6가지 분류를 한번에 검정하기 위해 반복문을 사용하였습니다.
for(i in c(1:6)) {
testing <- cbind(chi_df[,i]/1000000, rep(sum(chi_df[,i]) / 12, 12)/1000000)
res_df[i] <- chisq.test(testing, correct = F)$p.value
}
조회 수의 수의 크기가 크기 때문에 100만으로 나누어 정규화하였습니다. 카이 제곱 검정을 수행한 결과의 p-value 는 다음 표로 정리하였습니다.
| Economy | IT | Life_Cult | Politics | Society | World |
|---|---|---|---|---|---|
| 0.0000 | 0.7604 | 0.0000 | 0.0000 | 0.0000 | 0.4039 |
2.1.4 Result
- 월간 총 조회수 검정 결과, IT(0.76)와 세계(0.40)는 p-value 가 0.05 이상으로 귀무 가설이 채택되없습니다. 따라서 IT와 세계 섹션은 일 년 평균의 조회수와 각 월의 조회수가 차이가 없는 것으로 나타났습니다.
- 그리고 경제(0), 문화(0), 정치(0), 사회(0) 섹션은 p-value 가 0.05 이하로 귀무 가설이 기각 됨으로 인해 일 년 평균 조회수와 각 월의 조회수가 차이가 있는 것으로 나타났습니다.
2.2 Monthly Comment Data
귀무 가설 : 각 분류의 댓글 수는 일 년 평균의 댓글 수와 차이가 없다.
데이터는 각 분류의 월별 comment 합계를 사용했으며, 각 행은 1월부터 12월까지 입니다.
2.2.1 Data Pre-processing
데이터 전처리는 조회 수 데이터와 같습니다.
2.2.2 Visualisation
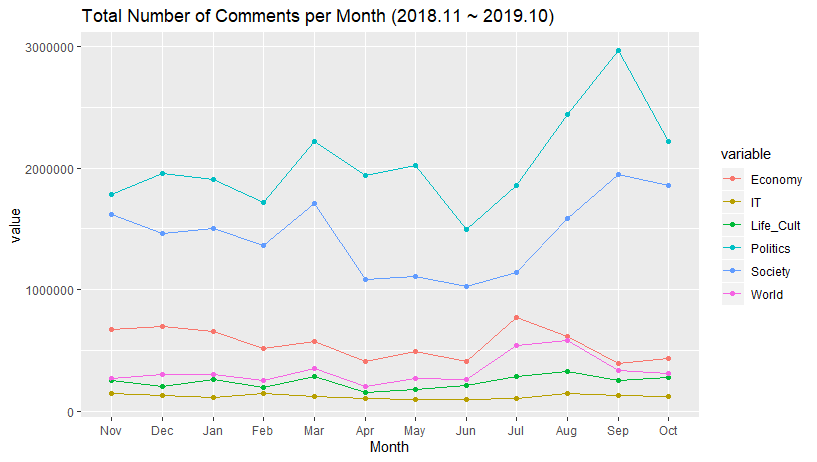
위 그래프를 보면 일 년간의 댓글 수의 추이를 볼 수 있습니다.
- 정치와 사회 섹션은 대체로 비슷한 모양을 보이며 변동폭이 크다는 것을 볼 수 있으며, 경제와 세계 섹션은 정치, 사회에 비해 적은 변동폭을 볼 수 있지만 IT와 문화섹션은 변동이 비교적 적은 것을 볼 수 있습니다
- 정치 뉴스에 대한 댓글 수가 일년동안 1위를 차지한 것을 확인할 수 있으며, 또다시 IT 뉴스에 관한 댓글 수가 꼴찌를 차지한 것을 볼 수 있습니다
2.2.3 Test
그래프로 확인 할 수 있는 부분을 카이 제곱 분석을 통해 확인해 보겠습니다. 6가지 분류를 한번에 검정하기 위해 반복문을 사용하였습니다.
for(i in c(1:6)) {
testing <- cbind(chi_df[,i]/10000, rep(sum(chi_df[,i]) / 12, 12)/10000)
res_df[i] <- chisq.test(testing, correct = F)$p.value
}
댓글 수의 크기가 크기 때문에 1만으로 나누어 정규화하였습니다. 카이 제곱 검정을 수행한 결과의 p-value 는 다음 표로 정리하였습니다.
| Economy | IT | Life_Cult | Politics | Society | World |
|---|---|---|---|---|---|
| 0.1171 | 0.9994 | 0.8414 | 0.0000 | 0.0000 | 0.0747 |
2.2.4 Result
- 월간 총 댓글수는 IT(0.99)와 문화(0.84), 경제(0.11), 세계(0.07) 섹션에서 p-value가 0.05 이상으로 일 년 평균의 댓글 수와 각 월의 댓글 수가 서로 차이가 없는 것으로 나타났습니다
- 정치(0), 사회(0)는 p-value가 0.05 이하로 귀무 가설이 기각되었습니다. 이는 정치와 사회 카테고리의 댓글 수는 월별 평균과 차이가 있음으로 결론지을 수 있습니다.
2.3 Conclusion
네이버 뉴스 기사에서 IT, 세계 섹션은 일 년 내내 평이한 조회 수와 댓글 수가 달리며, 정치와 사회 섹션은 일 년간 조회 수와 댓글 수의 변동이 크다는 것을 알 수 있습니다. 급격하게 조회수 및 댓글 수가 올라가는 시점의 기사 제목과 내용을 분석해보면 의미 있는 결과가 나올 것으로 추정됩니다.
3 F-Test
두 집단 모분산비 검정, 즉 두 집단이 서로 동질한지 검정하는 F-test 를 수행해보았습니다.
데이터 셋은 카이 제곱 검정과 같으며, 시각화도 같게 나옵니다.
3.1 Monthly View Data
귀무 가설 : 두 뉴스 분야의 월별 조회 수 분포 모양이 동질적이다.
3.1.1 Test
각 분류끼리 동질성 검사를 하기 위해 for 문을 2개 돌립니다. stat 기본 패키지의 var.test() 함수를 사용해 검사를 시행했습니다.
for(i in c(1:6)) {
for(j in c(1:6)) {
test <- var.test(x=ViewTotaldf[,i], y=ViewTotaldf[,j])
resultDf[i,j] <- round(test$p.value, 4)
}
}
resultDf 를 살펴보면 다음과 같습니다 :
| Economy | IT | Life_Cult | Politics | Society | World | |
|---|---|---|---|---|---|---|
| Economy | 1 | 0.0002 | 0.8079 | 0.6159 | 0.0091 | 0.0545 |
| IT | 0.0002 | 1 | 0.0003 | 0.0007 | 0 | 0.0322 |
| Life_Cult | 0.8079 | 0.0003 | 1 | 0.7955 | 0.0048 | 0.0897 |
| Politics | 0.6159 | 0.0007 | 0.7955 | 1 | 0.0024 | 0.1466 |
| Society | 0.0091 | 0 | 0.0048 | 0.0024 | 1 | 0 |
| World | 0.0545 | 0.0322 | 0.0897 | 0.1466 | 0 | 1 |
3.1.2 Result
- 조회수 랭킹 기사의 F-Test 결과를 보면, p-value 가 0.05 이상인 뉴스 섹션들은 경제/문화(0.80), 경제/정치(0.61), 경제/세계(0.05), 문화/정치(0.79), 문화/세계(0.08), 정치/세계(0.14) 섹션이 각각 채택되었습니다.
- 이로 인해 경제와 문화, 경제와 정치, 경제와 세계, 문화와 정치, 문화와 세계, 정치와 세계, 총 6개 섹션의 분포와 모양이 서로 비슷하다고 결론지을 수 있습니다.
3.2 Monthly Comment Data
귀무 가설 : 두 뉴스 분야의 월별 댓글 수 분포 모양이 동질적이다.
3.2.1 Test
각 분류끼리 동질성 검사를 하기 위해 for 문을 2개 돌립니다. stat 기본 패키지의 var.test() 함수를 사용해 검사를 시행했습니다.
for(i in c(1:6)) {
for(j in c(1:6)) {
test <- var.test(x=CmtTotaldf[,i], y=CmtTotaldf[,j])
resultDf[i,j] <- round(test$p.value, 4)
}
}
resultDf 를 살펴보면 다음과 같습니다 :
| Economy | IT | Life_Cult | Politics | Society | World | ||
|---|---|---|---|---|---|---|---|
| Economy | 1 | 0 | 0.0055 | 0.0012 | 0.0074 | 0.6721 | |
| IT | 0 | 1 | 0.0019 | 0 | 0 | 0 | |
| Life_Cult | 0 | 0055 | 0.0019 | 1 | 0 | 0 | 0.0161 |
| Politics | 0 | 0012 | 0 | 0 | 1 | 0.4906 | 0.0003 |
| Society | 0 | 0074 | 0 | 0 | 0.4906 | 1 | 0.0024 |
| World | 0 | 6721 | 0 | 0.0161 | 0.0003 | 0.0024 | 1 |
3.2.2 Result
- 댓글수 랭킹 기사의 F-Test 결과를 보면, p-value 가 0.05 이상인 뉴스 섹션들은 경제/세계(0.6721), 사회/정치(0.4906) 섹션이 각각 채택되었습니다.
- 따라서, 경제와 세계, 사회와 정치 섹션의 분포의 모양이 서로 비슷하다고 결론지을 수 있습니다.
3.3 Conclusion
댓글 수 랭킹 기사는 사회와 정치, 경제와 세계의 분포 모양이 동질하다는 분석 결과로 인해 이 두 그룹은 어떤 사건이 발생할 때 비슷한 경향의 관심도(댓글 수 및 조회 수)를 보여준다고 볼 수 있습니다.
조회수 랭킹 기사는 전체 15가지의 경우의 수 중에 6가지의 경우가 채택되었습니다. 교차표를 살펴보면 IT 와 사회 섹션의 경우 다른 섹션과 비슷한 성질의 분포 모양을 가지지 않는다는 것을 알 수 있습니다. 따라서 IT와 사회를 제외한 섹션들은 대체로 비슷한 경향을 가지지만, IT와 사회 섹션은 다른 분야의 뉴스 조회수와 무관한 경향을 가집니다.
4 Decision Tree
의사 결정 트리를 통해 댓글 작성자의 성별과 연령대 데이터를 통해 뉴스 분류를 예측하는 방법을 알아보겠습니다.
4.1 Planning
- 종속 변수는 카테고리, 독립 변수는 성별과 연령을 두어 성별과 연령대를 전체 댓글 수에 비례하도록 나눕니다.
- 특정 연령, 성별을 넣었을 때, 뉴스 분류가 결정되도록 합니다.
4.2 Dataset Production
저희가 지금 가지고 있는 데이터는 댓글 성별 비율 및 연령대 비율입니다. 이 비율을 전체 댓글 수에 곱해서 raw data 를 도출하였습니다.
for(i in c(1:nrow(tree_df))) {
for(j in c(5:12)) {
tree_df[i,j] <- round(tree_df[i,1] * tree_df[i,j] / 100, 2)
}
}
그 결과, 다음과 같은 데이터셋이 도출 되었습니다 :
| MALER | FEMALER | X10 | X20 | X30 | X40 | X50 | X60 | cat |
|---|---|---|---|---|---|---|---|---|
| 2021.04 | 384.96 | 0 | 168.42 | 721.8 | 890.22 | 457.14 | 168.42 | E |
| 644.91 | 132.09 | 7.77 | 108.78 | 225.33 | 256.41 | 132.09 | 46.62 | E |
| 463.55 | 171.45 | 6.35 | 25.4 | 165.1 | 247.65 | 133.35 | 57.15 | E |
| 489.01 | 129.99 | 6.19 | 105.23 | 191.89 | 167.13 | 105.23 | 43.33 | E |
| 505.8 | 56.2 | 0 | 16.86 | 118.02 | 213.56 | 157.36 | 56.2 | E |
Training 데이터와 Test 데이터를 샘플링하기 위해 caret 패키지의 createDataPartition() 함수를 사용하였습니다. 이 때, Training 데이터의 비율은 80% 로 하였습니다.
idx <- createDataPartition(y=treeData$cat, p=0.8, list=F)
train <- treeData[idx,]
test <- treeData[-idx,]
4.3 Algorithm Selection
의사 결정 트리를 생성하는데에는 여러 알고리즘이 있습니다. 뉴스 댓글 작성자 데이터를 넣고 적절한 결과를 도출하는 알고리즘을 선택하였습니다.
4.3.1 tree Package
treeMod <- tree(cat ~ ., data=train)
plot(treeMod)
tree 패키지의 tree() 함수를 사용해 실행한 결과, 다음과 같은 에러가 발생했습니다.
Error in plot.tree(treeMod) : cannot plot singlenode tree
싱글 노드 tree 가 생성되어 그래프로 시각화를 하지 못하는 결과를 에러가 발생했습니다. 따라서, tree 알고리즘은 좋지 않은 선택이라고 결정하였습니다.
4.3.2 party Package
ctreeMod <- ctree(cat ~ ., data=train)
plot(treeMod)
party 패키지의 ctree() 함수를 사용해 실행한 결과, tree 알고리즘과 동일한 에러가 발생했습니다.
4.3.3 rpart Package
rpartMod <- rpart(cat ~ ., data=train, method="class")
rpart 패키지의 rpart() 함수를 이용해 실행한 결과, 오류가 발생하지 않고 분기 지점을 잘 도출해낸 것을 확인할 수 있었습니다.
rpartMod 변수를 출력해 보면 다음과 같습니다 :
n= 52506
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 52506 43755 E (0.17 0.17 0.17 0.17 0.17 0.17)
2) X40< 184.12 30066 21582 I (0.19 0.28 0.26 0.0079 0.019 0.24)
4) X50< 22.545 15771 8623 I (0.036 0.45 0.34 0 0.0013 0.17)
8) FEMALER< 25.195 13420 6573 I (0.021 0.51 0.3 0 0.00015 0.17) *
9) FEMALER>=25.195 2351 1005 L (0.12 0.13 0.57 0 0.0077 0.18) *
5) X50>=22.545 14295 9172 E (0.36 0.093 0.18 0.017 0.039 0.31)
10) FEMALER< 108.6 12379 7669 E (0.38 0.1 0.15 0.013 0.012 0.34)
20) X10< 0.315 4928 2395 E (0.51 0.07 0.14 0.012 0.012 0.25) *
21) X10>=0.315 7451 4481 W (0.29 0.13 0.16 0.014 0.012 0.4) *
11) FEMALER>=108.6 1916 1224 L (0.22 0.027 0.36 0.039 0.22 0.14) *
3) X40>=184.12 22440 13928 P (0.14 0.012 0.039 0.38 0.36 0.069)
6) X60< 117.45 10789 5734 S (0.22 0.022 0.067 0.11 0.47 0.12) *
7) X60>=117.45 11651 4297 P (0.062 0.0023 0.013 0.63 0.27 0.025) *
의사 결정 트리를 보면 train 데이터가 가진 속성으로 적절하게 나누어 최종노드(*으로 표시되어있다)까지 잘 분기되는 모습을 볼 수 있습니다.
4.4 Visualisation
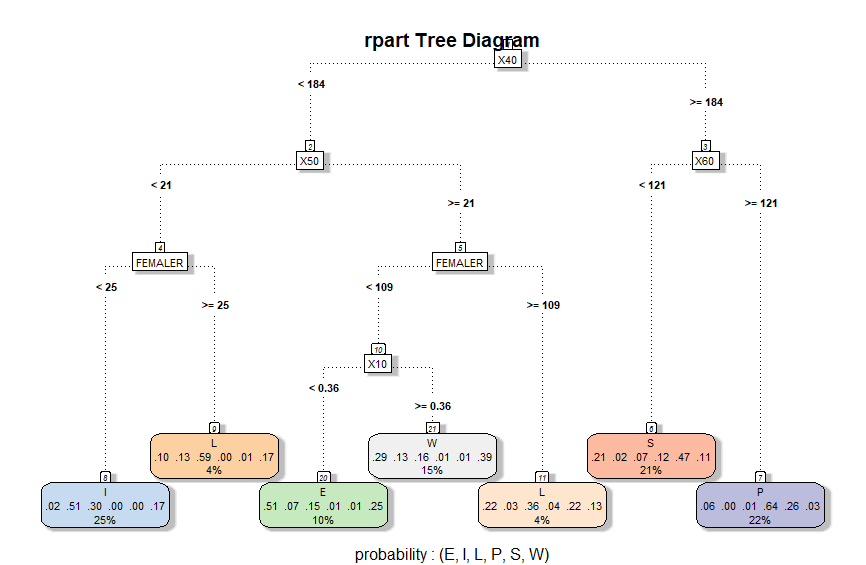
시각화된 의사 결정 트리를 통해 최종 노드까지 분기되는 과정을 짚어보면, 최상단 분기 지점(1)에서 40대 댓글수를 통해 분기하며, 다음 레벨의 분기 지점에서는 각각 50대(2), 60대(3) 댓글수를 통해 나뉩니다. 다음 레벨의 분기 지점(4, 5)에서 여성의 댓글수를 통해 나뉘고, 마지막 분기 지점에서 10대(10)의 댓글 수를 통해 분기 됩니다.
모든 train 데이터의 각 노드별 분기 기대값은 각각 1/6 확률(16%) 이였지만 IT 노드로 간 데이터는 전체의 25%, 생활은 4%(9)와 4%(11) 총 8%, 경제는 10%, 세계는 15%, 사회 21% 그리고 정치는 22% 비율로 도달했습니다.
각 분야로 분기되는 과정을 알아보겠습니다 :
- IT : 40대 댓글이 184개 미만이고, 50대 댓글이 21개 미만이며, 여자 댓글 수가 25개 미만인 경우
- Life/Culture :
- 40대 댓글이 184개 미만이고, 50대 댓글이 21개 미만이며, 여자 댓글 수가 25개 이상인 경우
- 40대 댓글이 184개 미만이고, 50대 딧글이 21개 이상이며, 여자 댓글 수가 109개 이상인 경우
- Economy : 40대 댓글이 184개 미만이고, 50대 댓글이 21개 이상이며, 여자 댓글 수가 109개 미만이고, 10대 댓글이 없을 경우
- World : 40대 댓글이 184개 미만이고, 50대 댓글이 21개 이상이며, 여자 댓글 수가 109개 미만이고, 10대 댓글이 있을 경우
- Society : 40대 댓글이 184개 이상이고, 60대 댓글이 121개 미만인 경우
- Politics : 40대 댓글이 184개 이상이고, 60대 댓글이 121개 이상인 경우
4.5 Decision Tree Prediction
predict() 함수를 통해 의사 결정 트리의 모델을 이용하여 test 데이터를 넣고 정확도를 계산하였습니다. 정확도를 계산하기 위해 caret 패키지의 confusionMatrix() 함수를 사용했습니다.
confusionMatrix(factor(test$cat), predict(rpartMod, test, type = "class"))
그 결과 :
Confusion Matrix and Statistics
Reference
Prediction E I L P S W
E 2460 456 0 1570 661 322
I 529 4091 0 153 200 496
L 664 2241 0 503 1726 335
P 523 55 0 4483 262 146
S 861 19 0 1743 2561 285
W 1373 1495 0 1169 734 698
Overall Statistics
Accuracy : 0.4356
위 결과를 보면 예측 데이터에 생활 데이터가 없다고 나타났습니다. 또한, 전체 정확도는 43.56% 가 나왔습니다.
4.6 Conclusion
네이버 뉴스 댓글의 속성으로 의사 결정 트리 알고리즘을 선정하기 위해 3가지 알고리즘을 시도해보았습니다. 그 중 tree 와 party 패키지의 알고리즘은 에러가 발생하여 rpart 패키지 알고리즘을 이용하여 의사 결정 트리를 생성했습니다.
생성된 의사 결정 트리를 이용하여 test 데이터를 예측해본 결과 정확도가 43.56%가 나왔습니다. 따라서, 의사 결정 트리는 네이버 뉴스 댓글 속성으로 뉴스 분류를 예측하기에 적합하지 않은 알고리즘으로 판단하였습니다.
5 Artificial Neural Network
인공 신경망 알고리즘이 구현된 nnet 과 neuralnet 패키지를 이용하여 네이버 댓글의 속서으로 뉴스 카테고리 예측을 해보겠습니다.
5.1 Dataset
예측할 데이터의 독립 변수를 늘리기 위해 이때까지 사용한 성별과 연령대 컬럼 외에 추가적으로 총 댓글 수, 삭제된 댓글 수, 규정 미준수 댓글 수까지 합쳐서 사용하였습니다.
nnet 패키지의 nnet() 함수를 사용하기위해 독립 변수에 one-hot encoding 이 필요합니다.
5.2 one-hot encoding
section 컬럼을 one-hot encoding 하기 위해 nnet 패키지의 class.ind() 함수를 사용하였습니다.
section.ind <- class.ind(NewsData$section)
NewsDataE <- cbind(NewsData, section.ind)
그 결과, NewsDataE 데이터 프레임은 다음과 같이 변하였습니다 :
| … | section | Economy | IT | Life_Cult | Politics | Society | World |
|---|---|---|---|---|---|---|---|
| … | Life_Cult | 0 | 0 | 1 | 0 | 0 | 0 |
| … | IT | 0 | 1 | 0 | 0 | 0 | 0 |
| … | Economy | 1 | 0 | 0 | 0 | 0 | 0 |
| … | World | 0 | 0 | 0 | 0 | 0 | 1 |
| … | Life_Cult | 0 | 0 | 1 | 0 | 0 | 0 |
| … | World | 0 | 0 | 0 | 0 | 0 | 1 |
5.3 Training & Test Data Selection
One-hot encoding 된 데이터들의 80%를 trian 데이터로 정하고, 나머지 20%를 test 데이터로 정하였습니다. 이 때, 원본 데이터의 각 행을 구별하기 위해 다음과 같이 전처리를 하였습니다.
Elen <- nrow(subset(NewsDataE, section == "Economy"))
Ilen <- nrow(subset(NewsDataE, section == "IT"))
...
Ei <- sample(c(1:Elen), 0.8*Elen)
Ii <- sample(c(1:Ilen), 0.8*Ilen)
...
idx <- c(
Ei,
Ii + Elen,
Li + Elen + Ilen,
Pi + Elen + Ilen + Llen,
Si + Elen + Ilen + Llen + Plen,
Wi + Elen + Ilen + Llen + Plen + Slen
)
trData <- NewsDataE[idx,]
teData <- NewsDataE[-idx,]
각 행의 길이를 구하고 시작점을 찾기 위해 다음 column 으로 갈 떄 이전 column 의 길이를 더한 index 값을 설정하여 train 과 test 데이터를 만들었습니다.
이렇게 한 이유는 모든 섹션 데이터의 80%를 얻기 위해서 입니다. 그냥 전체 데이터에서 80%를 뽑으면 한 섹션에 대한 학습이 덜 될 수 있으므로, 동등한 데이터 양에서 학습하여 학습 최대치를 얻기 위해 이렇게 하였습니다.
5.4 Model Creation
nnet() 함수의 매개변수는 여러가지가 있지만 그 중에 x, y, softmax, size 만 사용하여 모델을 생성하였습니다. nnet 모델을 생성하기 위해 x 에 1열부터 11열까지(댓글 속성), y 에 13열부터 18열까지(one-hot encoding 된 카테고리)를 넣었으며, softmax 에 True 값을 넣어 각 값들 사이가 보간(interpolate)되도록 했습니다.
trX <- trData[,c(1:11)]
trY <- trData[,c(13:18)]
teX <- teData[,c(1:11)]
nnModel <- nnet(x=trX, y=trY, size=15, softmax=T)
nnet() 함수가 시행되면서 다음과 같이 출력창에 값이 모이는 것을 확인할 수 있습니다.
# weights: 276
initial value 109595.533387
iter 10 value 88784.254272
iter 20 value 83903.432492
iter 30 value 76683.557201
iter 40 value 72820.532824
iter 50 value 71768.875055
iter 60 value 71330.444224
iter 70 value 70551.945893
iter 80 value 69642.710653
iter 90 value 68783.966017
iter 100 value 67949.304016
final value 67949.304016
stopped after 100 iterations
만들어진 nnModel 을 시각화 해보았습니다. 시각화를 하기 위해 nnet plot 함수를 별도로 다운로드 받았습니다.
source_url('https://gist.githubusercontent.com/fawda123/7471137/raw/466c1474d0a505ff044412703516c34f1a4684a5/nnet_plot_update.r')
plot.nnet(nnModel)
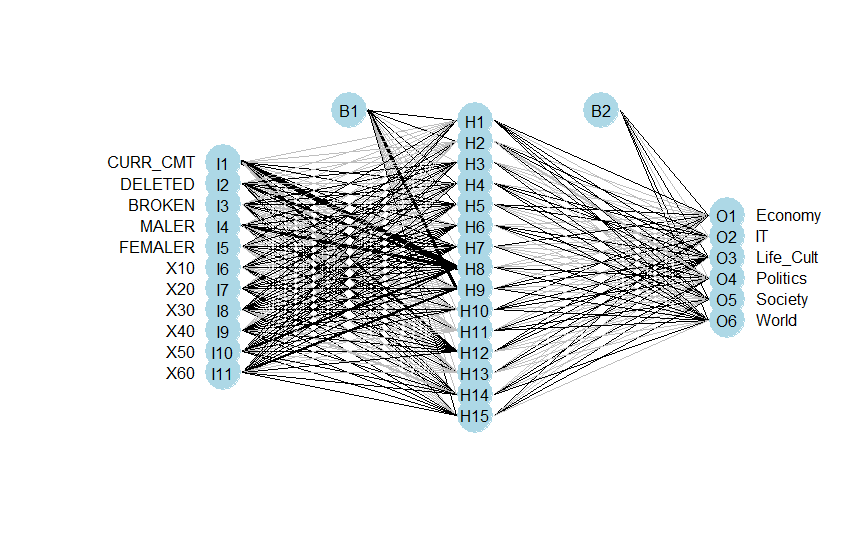
시각화된 nnet 모델을 보면 hidden 계층이 하나 있고, 독립 변수 11개, 종속 변수 6개와 bias 값이 있는 것을 확인할 수 있습니다.
5.5 Model Prediction
nnet 의 결과인 모델을 이용하여 test 데이터로 예측을 수행합니다. 예측을 위해 predict() 함수를 사용했습니다. 예측 결과를 테이블로 만들어 정확도를 계산했습니다.
nnPrediction <- predict(nnModel, teX, type="class")
predTable <- table(nnPrediction, teData$section)
| Economy | IT | Life_Cult | Politics | Society | World | |
|---|---|---|---|---|---|---|
| Economy | 765 | 216 | 183 | 11 | 24 | 407 |
| IT | 93 | 1423 | 557 | 0 | 6 | 342 |
| Life_Cult | 243 | 353 | 956 | 9 | 54 | 663 |
| Politics | 160 | 10 | 59 | 1694 | 586 | 87 |
| Society | 795 | 154 | 338 | 441 | 1493 | 449 |
| World | 132 | 32 | 95 | 33 | 25 | 240 |
교차표로 결과값을 비교한 결과를 바탕으로 정확도를 계산하였습니다.
calcAcc <- function(compTable) {
len <- nrow(compTable)
total <- 0
for(l in c(1:len)) { total <- total + compTable[l,l] }
accuracy <- round((total / sum(compTable)) * 100, 2)
return(accuracy)
}
predAccuracy <- cat(calcAcc(predTable), "%\n")
# 50.05 %
모델 예측 정확도는 50.05%가 나왔습니다. 평균 예측 정확도를 얻기 위해 4번 더 반복하여 시각화하고 평균치를 구했습니다.
df=data.frame(x=c(1:5), y=c(50.05, 50.53, 44.24, 56.92, 50.68))
ggplot(data=df, mapping=aes(x=x, y=y, col=x, fill=x)) +
geom_col(position="identity", show.legend=F) +
geom_text(label=paste(df$y, "%"), nudge_y=2, color="black") +
geom_hline(aes(yintercept=mean(df$y))) +
geom_text(x=3, y=51, label=paste("mean :", mean(df$y)), check_overlap=T, color="Red") +
labs(title="nnet result", x="Tries", y="Percentage")
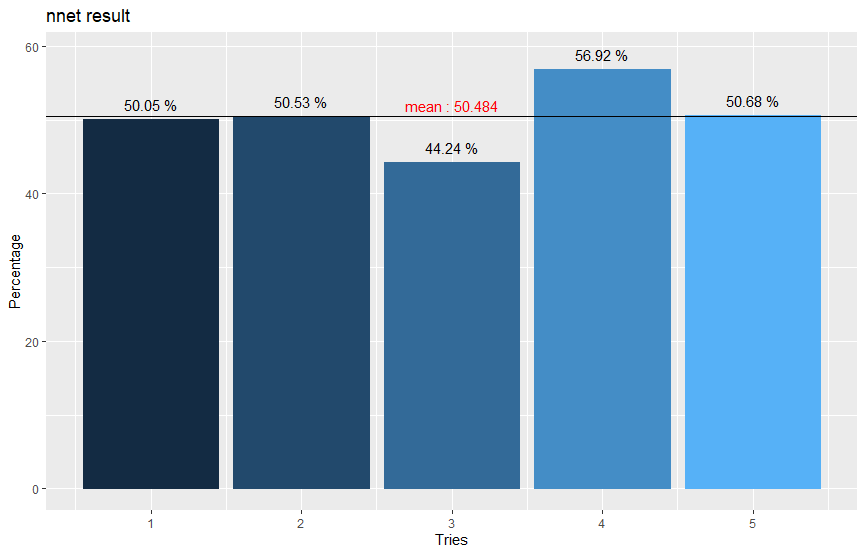
평균값은 50.484%가 나왔으며 기대한 것보다 매우 낮다는 것을 확인할 수 있습니다.
5.6 Conclusion
인공신경망 알고리즘을 구현한 nnet 패키지를 이용하여 네이버 뉴스 댓글의 속성으로 카테고리 예측을 해보았습니다. 5번 수행한 결과 평균 50.484%의 예측 정확도를 도출하였고, 이는 곧 데이터 분석에 적합하지 않다는 결론을 내릴 수 있었습니다.
6 Cluster Analysis
네이버 댓글 작성자의 속정을 독립 변수로 하여 댓글 작성자 속성별 군집 분류를 하고, 이를 분석해 보겠습니다.
6.1 Dataset
의사 결정 트리에서 사용한 데이터셋을 사용합니다. 네이버 정책에 따른 뉴스의 총 댓글 수가 100개 미만인 경우, 성별과 연령대 댓글 비율 정보를 제공하지 않기 때문에, 백프로 제공되는 30대의 댓글 비율이 0이아닌 경우만을 적합한 데이터로 선정하였습니다.
df <- subset(df, df$X30 != 0)
df <- changeNum(df)
changeNum() 함수는 비율 데이터를 수치화하는 커스텀 함수입니다.
군집화를 할 때, Vector 메모리 부족과 덴드로그램을 그릴 때 session abort 가 떠서 적정 수치로 샘플링을 하였습니다. 이 프로젝트에서는 5%(3281개)의 샘플 데이터를 이용하였습니다.
idx <- sample(1:nrow(df), 0.05 * nrow(df))
df <- df[idx, ]
군집 분석에 필요한 데이터는 텍스트 데이터가 아닌 정수형 데이터를 넣어야 하기 때문에 뉴스 카테고리를 정수로 표현하였습니다 :
- 경제(1), IT(2), 생활/문화(3), 정치(4), 사회(5), 세계(6)
df$type <- ifelse(df$cate == 'E', 1,
ifelse(df$cate == 'I', 2,
ifelse(df$cate == 'L', 3,
ifelse(df$cate == 'P', 4,
ifelse(df$cate == 'S', 5, 6)))))
6.2 Distance Calculation
각 행(데이터)의 거리를 측정하기 위해 유클리디언 거리 측정법으로 계산하였습니다. 기존 dataset 의 2열부터 9열까지의 속성(성별, 연령대)를 독립 변수로 지정하고 유클리디언 거리를 측정하였습니다.
target <- sampling[,4:11]
gender_type_dist <- dist(target, 'euclidean')
gender_type_dist 변수를 출력해보면 다음과 같이 나옵니다 :
| 4881 | 32733 | 44421 | 10192 | 50251 | 29771 | |
|---|---|---|---|---|---|---|
| 32733 | 29.782545 | |||||
| 44421 | 28.195744 | 12.961481 | ||||
| 10192 | 21.400935 | 19.467922 | 11.874342 | |||
| … | … | … | … | … | … | … |
6.3 Analysis
측정된 데이터간 거리를 바탕으로 평균 연결 방법(ave)을 통해 hclust() 함수를 사용하여 군집화를 수행했습니다.
gender_type_res <- hclust(gender_type_dist , method="ave")
Call:
hclust(d = gender_type_dist, method = "ave")
Cluster method : average
Distance : euclidean
Number of objects: 260
그 결과 260개의 object 가 생성된 것을 확인할 수 있습니다.
그리고 군집화된 데이터를 시각화 해보았습니다.
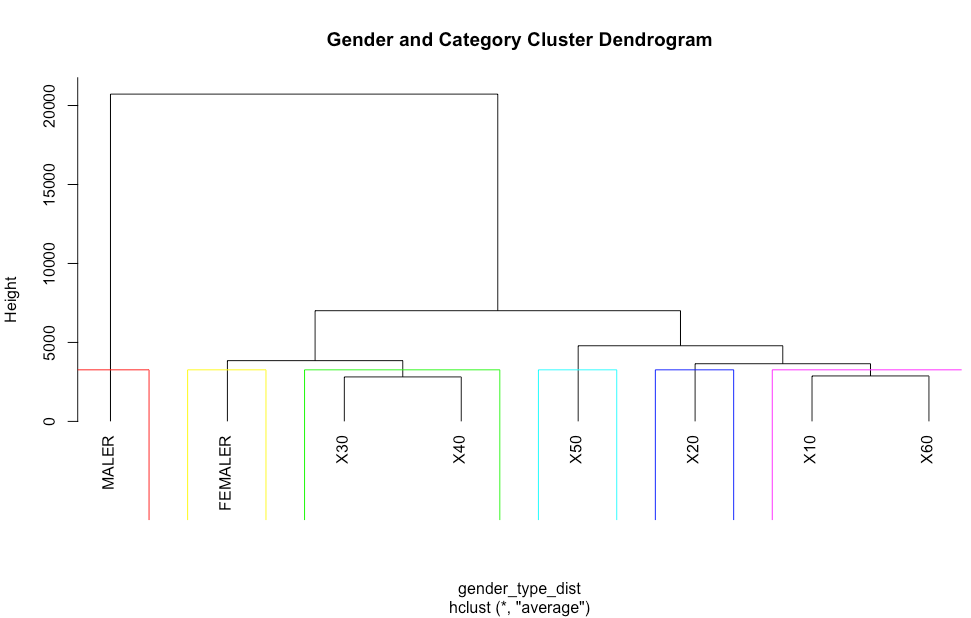
남성과 여성, 그리고 20대, 30/40대, 50대, 10/60대로 군집된 것을 볼 수 있습니다.
최적의 k 값을 도출하기 위해 k 를 1부터 10까지 변화시키며, witness 값이 급격하게 변하는 Elbow point 를 구했습니다.
maxlen <- 10
for(i in 1:maxlen){
wss[i] <- sum(kmeans(target, centers = i)$withinss)
}
wss # witness
변화하는 witness 의 값을 시각화하면 다음과 같습니다 :
plot(1:10, wss, type="b",xlab = "Number of Clusters", ylab = "Within group sum of squares")
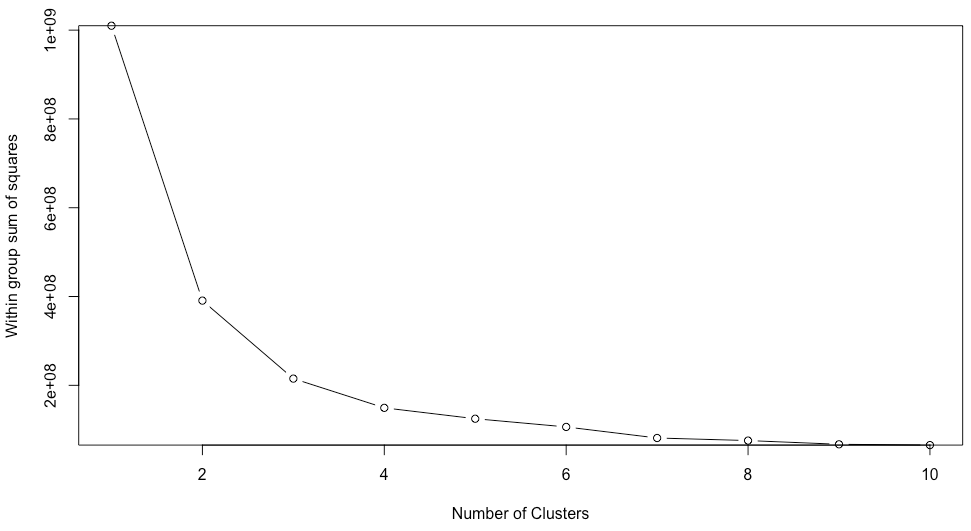
그래프를 확인해보면 완만해지는 부분(Elbow point)가 4로 추정됩니다. 따라서 Elbow point 를 4로 설정하였습니다. 설정된 값을 이용해 k-means 군집을 하고 시각화 해보았습니다.
kms <- kmeans(target , elbow)
plot(target , col = kms$cluster)
K-means clustering with 4 clusters of sizes 26, 371, 136, 5
Cluster means:
MALER FEMALER X10 X20 X30 X40
1 3640.483 1188.40192 40.665769 486.08385 1182.2319 1520.3785
2 338.936 97.85968 4.491024 46.23863 114.9720 143.0425
3 1335.988 458.10794 12.677647 160.39625 439.5718 589.7121
4 7813.844 3909.55600 126.162000 1285.68800 3004.7820 3785.5340
X50 X60
1 1085.32385 500.55192
2 89.27108 38.91423
3 407.20007 181.85154
4 2564.49000 969.41200
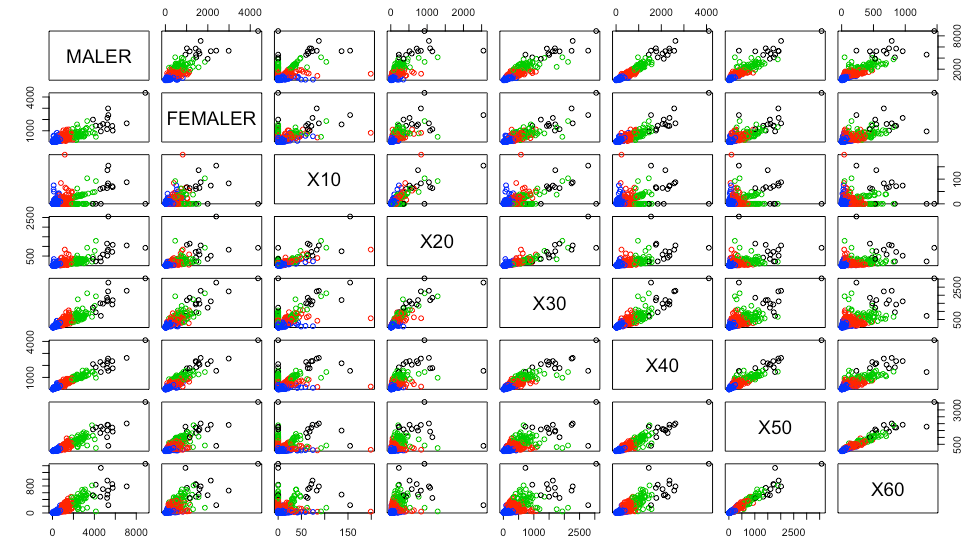
k-means 군집이 된 위 그래프를 보면, 대체로 선ㅂ명하게 4가지로 분류된 것을 볼 수 있습니다. 하지만 10대와 교차되는 데이터들은 다른 분류와 다르게 섞여있는 것을 확인할 수 있습니다. 이 는, 10대 데이터의 가짓수가 다른 컬럼에 비해 비교적으로 많이 적어서 생기는 문제로 확인됩니다.
6.4 Dividing Group
군집 분석 결과를 앞서 도출된 Elbow point 인 4개의 대상의 군집수를 지정하기 위해 cutree() 함수를 사용합니다. 관측치를 대상으로 4개의 군집수를 지정하여 군집을 의미하는 숫자(1~4)가 출력 됩니다.
ghc <- cutree(gender_type_res, k = K)
군집수(ghc)를 기존 데이터셋의 컬럼에 추가하고, 군집수의 빈도를 구하였습니다. 그리고 각 그룹의 요약을 출력하고 그 그룹의 평균을 table 로 표현하였습니다.
sampling$ghc <- ghc
table(sampling$ghc)
for(i in c(1:4)) {
g1 <- subset(sampling, ghc == i)
print(summary(g1[2:9]))
}
- 그룹별 빈도
| 1그룹 | 2그룹 | 3그룹 | 4그룹 |
|---|---|---|---|
| 210 | 1 | 2 | 37 |
- 그룹별 요인 평균
| 요인 | 1그룹 | 2그룹 | 3그룹 | 4그룹 |
|---|---|---|---|---|
| 남성 | 450 | 9112 | 6152 | 2027 |
| 여성 | 148 | 2570 | 2366 | 707 |
| 10대 | 6 | 116 | 0 | 16 |
| 20대 | 62 | 700 | 381 | 221 |
| 30대 | 157 | 2103 | 1412 | 629 |
| 40대 | 195 | 3972 | 2560 | 918 |
| 50대 | 123 | 3388 | 2641 | 654 |
| 60대 | 54 | 1402 | 1439 | 294 |
6.5 Summary Statistical Analysis
위 테이블을 보면 2그룹과 3그룹의 댓글 수는 많지만 빈도 수가 적어(1, 2개의 댓글에 불과) 정확한 판단이 어렵다는 것을 확인할 수 있습니다. 따라서 1그룹과 4그룹을 살펴보았습니다.
그룹별 요인 평균을 보면 1그룹의 경우 빈도는 210으로 가장 많지만, 전체 댓글의 경우 600개 밖에 되지 않습니다. 그러므로 대중의 관심도 측면에서 데이터의 가치가 저하된다고 볼 수 있습니다.
4그룹의 빈도 수는 37개이지만, 평균 댓글 수가 2700개에 달합니다. 따라서 빈도도 많으며 댓글 수도 높은 4그룹이 사람들의 관심도가 높은 기사 댓글군이라고 판단 하였습니다.
4그룹의 뉴스 섹션 분포를 도출하여 다음과 같은 결과를 얻었습니다 :
| 경제 | IT | 생활/문화 | 정치 | 사회 | 세계 |
|---|---|---|---|---|---|
| 4 | 3 | 10 | 2 | 23 | 3 |
4그룹의 구성요소는 문화와 사회 섹션이 다수로 판단되며, 문화와 사회 섹션의 제목의 경향을 알아보기 위하여 출력하였습니다.

위 기사 제목을 살펴보면 대체로 자극적인 단어와 부정적인 어휘를 사용하는 것을 확인할 수 있습니다. 따라서 뉴스를 보는 사람들은 자극적인 제목에 관심을 많이 보이며, 의사표현을 많이 한다는 것을 알 수 있었습니다.
6.6 Conclusion
군집 분석을 통해 댓글 통계를 가진 기사들은 비슷한 경향을 가진 그룹으로 분류될 수 있음을 보여주었습니다. 또한 각 유사한 특징을 가진 그룹들을 분석해본 결과 네이버 댓글수는 자극적인 제목에 반응이 더 크다는 것을 보여주며, 특히 문화와 사회 섹션의 기사에 많은 댓글이 달린다는 것을 알 수 있었습니다.
7 KNN
네이버 댓글 작성자의 성별과 연령대 데이터를 이용하여 뉴스 카테고리를 분류하는 지도 학습 알고리즘을 수행했습니다. 또한 학습된 모델을 통해 테스트 데이터를 통해 새로운 댓글 작성자의 데이터가 들어오면 알맞은 뉴스 섹션으로 분류 해보겠습니다.
7.1 Data Pre-processing
KNN 알고리즘을 적용하는데 사용할 데이터는 사회와 생활 섹션을 사용하였습니다. 두 섹션의 댓글수, 성별 비율, 연령대 비율과 섹션 컬럼을 가져오기 위해 다음과 같은 전처리 과정을 거쳤습니다. 또한 네이버 댓글 정책으로 인해 통계가 없는 데이터를 삭제하는 과정을 거쳤습니다.
S_training$cate <- substr(S_training$NEWSID, 1, 1)
S_training <- S_training[,c(-1,-7)]
C_training$cate <- substr(C_training$NEWSID, 1, 1)
C_training <- C_training[,c(-1,-7)]
tot_training <- rbind(S_training, C_training)
training <- tot_training[, c(6, 10:18)]
training <- training[,c(-1)]
| NCOMMENT | MALER | FEMALER | X10 | X20 | X30 | X40 | X50 | X60 | cate |
|---|---|---|---|---|---|---|---|---|---|
| 5897 | 73 | 27 | 2 | 11 | 24 | 34 | 22 | 8 | S |
| 2251 | 59 | 41 | 1 | 12 | 37 | 35 | 12 | 2 | S |
| 2066 | 73 | 27 | 0 | 10 | 34 | 36 | 15 | 5 | S |
| 2010 | 72 | 28 | 1 | 18 | 36 | 30 | 11 | 4 | S |
| 1464 | 52 | 48 | 3 | 21 | 35 | 29 | 9 | 3 | S |
| … | … | … | … | … | … | … | … | … | … |
7.2 Data Separation
Train, Test, Valid 데이터를 3:1:1 의 비율로 갖추고 입력(독립 변수)과 출력(종속 변수) 데이터로 분리하는 과정을 거쳤습니다.
idx <- sample(x = c("train", "valid", "test"), size = nrow(training), replace = TRUE, prob = c(3, 1, 1))
train <- training[idx == "train", ]
valid <- training[idx == "valid", ]
test <- training[idx == "test", ]
train_x <- train[, -9]
valid_x <- valid[, -9]
test_x <- test[, -9]
train_y <- train[, 9]
valid_y <- valid[, 9]
test_y <- test[, 9]
7.3 Applying KNN algorithm
전처리된 데이터셋을 KNN 알고리즘을 통해 학습 모델을 만들어 보겠습니다. train 파라미터에 train 데이터의 독립 변수를 넣으며, test 파라미터에 확인데이터(valid)의 독립 변수를 넣고, cl(class 변수)에 train 의 종속 변수를 넣었습니다. 또 k값은 1을 넣어 모델을 생성하여 정확도를 계산해 보았습니다.
knn_1 <- knn(train = train_x, test = valid_x, cl = train_y, k = 1, use.all = F)
table(knn_21, valid_y)
accuracy_21 <- sum(knn_21 == valid_y) / length(valid_y)
- 생성된 모델
[1] L L S S S S S S S S S S S L S S S S S S S S L S S S
[27] L S S S S S S S S S S S S S S S S L S S S S S S S S
[53] S L S S S L S S S S S S S S S S S S L S S S S S S S
[79] S L S S S S S L S L S S S S S S S S S S L S S S S S
- 분류된 결과의 Cross Table
| knn_21 | valid_y | |
|---|---|---|
| L | S | |
| L | 1125 | 233 |
| S | 216 | 1946 |
k 가 1일 때, 뉴스 섹션 분류 정확도는 87.24% 가량 나왔습니다.
7.4 Best k value
k 가 1부터 train 데이터의 행 개수 만큼 변화할 때 분류 정확도를 구하려 했습니다. 반복문을 이용하여 k 가 1부터 train 행 개수만큼 변화할 때, 분류 정확도가 몇 %가 되는지 그래프를 그려보고 최적의 k 값을 확인하였습니다.
- 분류 정확도를 사전 할당해 줍니다.
accuracy_k <- NULL
- k 가 1부터 train 데이터의 행 개수까지 반복합니다.
pb <- progress_bar$new(format="[:bar] :current/:total (:percent)", total=cnt)
cnt <- nrow(train)
for(idx in c(1:cnt)){
# k가 idx일 때 knn 적용
knn_k <- knn(train = train_x, test = valid_x, cl = train_y, k = idx)
# 분류 정확도 계산
accuracy_k <- c(accuracy_k, sum(knn_k == valid_y) / length(valid_y))
pb$tick(0)
pb$tick(1)
}
- 이 때, 12% 에서 에러가 발생했습니다.
[=========>----------------------------------------------------] 499/4188 ( 12%)
Error in knn(train = train_x, test = valid_x, cl = train_y, k = idx) :
too many ties in knn
- k 에 따른 분류 정확도 데이터를 생성하고 시각화를 해보았습니다.
valid_k <- data.frame(k = c(1:cnt), accuracy = accuracy_k)
plot(formula = accuracy ~ k, data = valid_k, type = "o", pch = 20, main = "validation - optimal k")
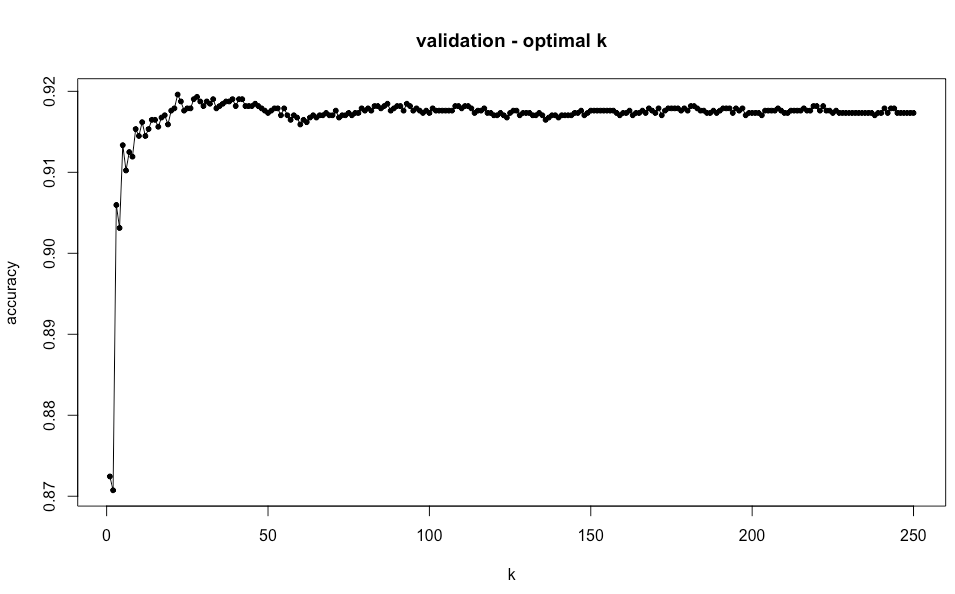
- 분류 정확도가 가장 높으면서, 가장 작은 k 값을 도출합니다.
sort(valid_k$accuracy, decreasing = T)
maxdata <- max(valid_k$accuracy)
min_position <- min(which(valid_k$accuracy == maxdata))
min_position 의 값과 그래프를 확인해보면 적정 k 값을 알 수 있습니다. 최적의 min_position 은 21이 나왔으며, 이 때 maxdata (최대의 분류 정확도)는 91.96%가 나왔습니다. k 가 1일때와 비교해보면 4% 가량 정확도가 높아진 것을 확인할 수 있습니다.
Applying KNN algorithm with the best k-value
최적의 k 값인 21을 이용하여 test 데이터에 적용한 모델을 생성했습니다.
knn_optimization <- knn(train = train_x, test = test_x, cl = train_y, k = min_position)
생성된 모델은 test 데이터와 비교하기 위해 Confusion Matrix 를 구성합니다.
result <- matrix(NA, nrow = 2, ncol = 2)
rownames(result) <- paste0("real_", c('S', 'L'))
colnames(result) <- paste0("clsf_", c('S', 'L'))
result[1, 1] <- sum(ifelse(test_y == "S" & knn_optimization == "S", 1, 0))
result[2, 1] <- sum(ifelse(test_y == "L" & knn_optimization == "L", 1, 0))
result[1, 2] <- sum(ifelse(test_y == "S" & knn_optimization == "L", 1, 0))
result[2, 2] <- sum(ifelse(test_y == "L" & knn_optimization == "S", 1, 0))
최종 결과는 다음과 같은 Confusion Matrix 로 나타났습니다.
| clsf_S | clsf_L | |
|---|---|---|
| real_S | 2226 | 43 |
| real_L | 1099 | 261 |
Final Accuracy Calculation
최적 k 값을 이용한 KNN 모델에 test 데이터를 넣어 분류하고, 그 정확도를 table 로 정리하였습니다.
table(prediction=knn_optimization, answer=test_y)
accuracy <- sum(knn_optimization == test_y) / sum(result)
accuracy
| 생활 | 사회 | |
|---|---|---|
| 생활 | 1099 | 43 |
| 사회 | 261 | 2226 |
k 가 21일 때 뉴스 섹션 분류 정확도는 최적의 k 값을 구했을 때 나왔던 91.96% 보다 조금 낮은 91.62%가 나왔습니다. 이는 최적 k 값을 사용하지 않은(k=1) 경우에 비해 4% 높은 결과가 나왔고, 이때까지 사용한 모든 알고리즘의 정확도보다 비교적으로 매우 높은 수치로 확인 되었습니다.
따라서 90% 이상의 정확도를 가진 분류 알고리즘으로 성공적인 예측을 할 수 있다는 결과를 도출하였습니다.
Final Conclusion
네이버 뉴스의 각 세션 별 댓글 및 조회 수 분석을 통해 비슷한 경향(동질성)의 뉴스 카테고리를 분류해보았습니다. 그리고 댓글 작성자 유형에 따른 섹션 예측 모델들을 의사 결정 트리, KNN, 인공 신경망으로 생성하고 예측 정확도를 도출했습니다. 그 결과 KNN 을 제외하면 절반 가량의 정확도를 보이며 예측이 불가능하다는 판단을 내렸으며, KNN 의 경우 k 가 21일때 카테고리 분류 정확도는 최고치인 91.62%가 나왔습니다. 이로 인해 KNN 알고리즘을 통한 네이버 댓글 작성자의 유형에 따라 어떤 카테고리에 관심도가 높은지 알 수 있으며, 타겟을 예측한 마케팅이 가능할 것으로 판단됩니다.
또한 분석 목표와 부합되는 의사 결정 트리와 군집 분석의 도출된 결과를 활용하여, 일명 ‘효율 지수’를 측정하였습니다. 이는 의사 결정 트리의 결정 수치(말단 노드의 채택 비율)와 군집 분석의 그룹별 관심도(빈도 / 전체 댓글 수)를 곱한 것을 칭하였습니다. 그 결과는 다음 표로 나타납니다.
| 분류 | IT | 생활/문화 | 경제 | 세계 | 사회 | 정치 |
|---|---|---|---|---|---|---|
| 의사결정 | 0.25 | 0.08 | 0.1 | 0.15 | 0.21 | 0.22 |
| 군집분석 | 0.07 | 0.22 | 0.09 | 0.07 | 0.51 | 0.04 |
| 효율지수 | 0.0167 | 0.0178 | 0.0089 | 0.0100 | 0.1073 | 0.0098 |
의사 결정 트리 및 군집 분석을 같이 고려한 결과,
- 사회 분야가 상당히 높다는 것을 확인 할 수 있습니다.
- 생활/문화와 IT 가 사회 분야에 비해 1/6 수준이라는 것을 확인할 수 있습니다.
- 나머지 분야는 사회 분야에 비해 1/10 수준이라는 것을 확인할 수 있습니다.
댓글 작성자 성배율은 3:1 (남자:여자) 이며, 소비지수*는 87.8, 92.1 (남자, 여자) 입니다.
- 소비지수는 소비자 특성별 소비 지출 전망(2019년 전반기)를 참고하였습니다.
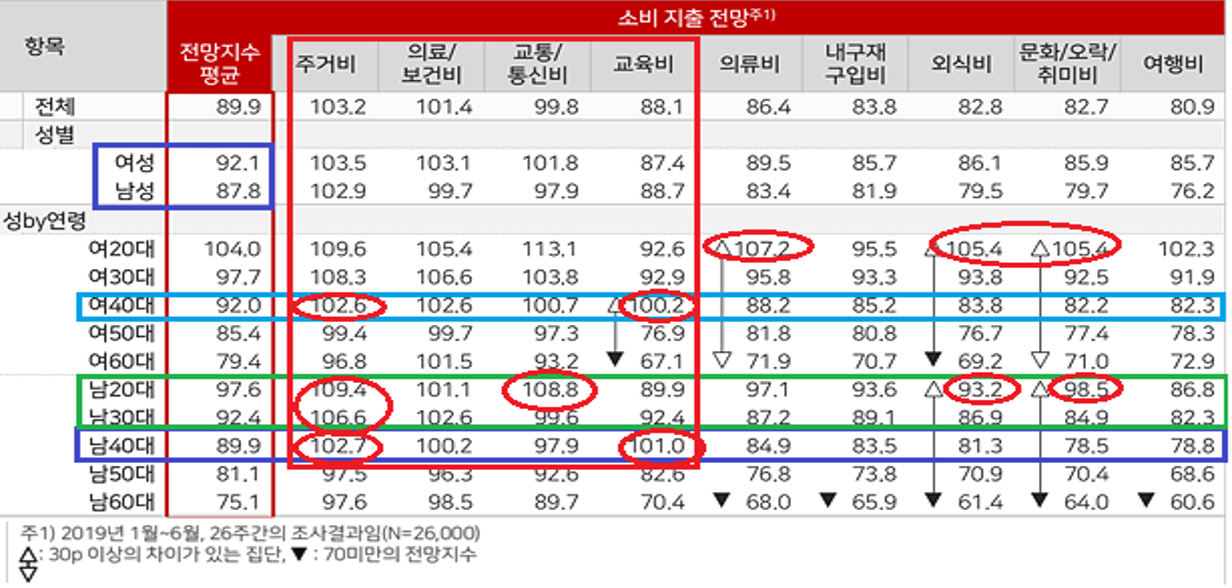
따라서, 네이버 뉴스에 광고를 추진한다면 관심도가 제일 높은 사회 뉴스를 활용하고, 사회 뉴스에서 강세를 보이는 40대 남성을 대상으로 한 상품이 다른 상품 대비 효율적일 것으로 판단됩니다. 소비 지출 지수(’19년 전반기 기준)에서 40대 남성과 여성이 모두 높은 수치를 보였던 주거와 교육 분야의 상품이 적절하다고 판단됩니다. 2,30대 남성을 대상으로 한 상품은 IT 뉴스 활용 및 광고 시 효율적일 것으로 판단되며, 특히, 소비 지출 지수에서 높은 수치를 보였던 주거 분야와 교통/통신 분야의 상품이 적절하다고 판단됩니다.
Sources
R을 이용한 Selenium 실행 (Windows 10 기준)
Progress bar in your R terminal
